本篇文章给大家带来了关于mysql的相关知识,其中主要介绍了explain的相关问题,Mysql中的explain堪称Mysql的性能优化分析神器,我们可以通过它来分析SQL语句的对应的执行的,希望对大家有帮助。

程序员必备接口测试调试工具:立即使用
Apipost = Postman + Swagger + Mock + Jmeter
Api设计、调试、文档、自动化测试工具
后端、前端、测试,同时在线协作,内容实时同步
推荐学习:mysql视频教程
数据库性能优化是每个后端程序猿必备的基础技能之一,而Mysql中的explain堪称Mysql的性能优化分析神器,我们可以通过它来分析SQL语句的对应的执行计划在Mysql底层到底是如何执行的,它对于我们评估SQL的执行效率以及确定Mysql的性能优化方向具有重要的意义。但是很多同学对于如何根据explain对已有SQL进行深度的执行分析还是丈二和尚摸不着头脑,因此本文详细阐述通过explain分析定位数据库性能问题。
explain基础
对于每个SQL来说,当它被客户端发送到Mysql服务端之后,会经过Mysql的优化器部件的分析,主要包括一些特殊的处理、执行顺序的改变以确保最优的执行效率,最终生成对应的执行计划。所谓的执行计划,实际就是在存储引擎层面如何获取数据的,是通过索引获取数据还是进行全表扫描获取数据,获取到数据后需不需要回表,等等,简单理解就是Mysql获取数据的过程。
接下来我们来详细看下,这个explain到底是何方神圣,为什么能指导我们进行性能优化。当我们执行如下语句:
explain SELECT * FROM user_info where NAME='mufeng'
执行explain语句之后,我们会得到如下的执行结果,这个类似数据库表的12个字段实际上就是对Mysql执行怎样的执行计划的详细描述。下面我们来好好研究下这12个字段分别代表什么意思,只有搞清楚它们的含义,我们才能明确Mysql到底是怎么执行数据查询的。

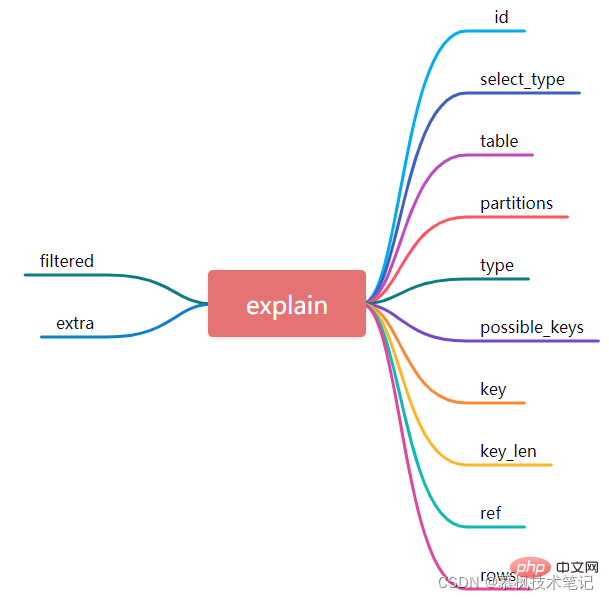
1、id
实际上每次select查询都会对应一个id,它代表着SQL执行的顺序,如果id值越大,说明对应的SQL语句执行的优先级越高。在一些复杂的查询SQL语句中常常包含一些子查询,那么id序号就会递增,如果出现嵌套查询,我们可以发现最里层的查询对应的id最大,因此也优先被执行。

如上图所示,SQL查询语句中,第一个执行计划的id为1,第二个执行计划的id为2,id为1的执行计划对应的table为order,id为2的执行计划对应的table是user_info,结合SQL语句,我们知道先执行子查询select id from user_info,而后再执行关于表order的数据查询。
2、select_type
select_type表示的执行计划的对应的查询是什么类型,常见的查询类型主要包括普通查询、联合查询以及子查询等。SIMPLE(查询语句为简单的查询不包含子查询)、PRIMARY(当查询语句中包含子查询的时候,对应最外层的查询类型)、UNION(union之后出现的select语句对应的查询类型会标记此类型)、SUBQUERY(子查询会被标记为此类型)、DEPENDENT SUBQUERY(取决于外面的查询 )

3、table
table代表表名称,表示要查询哪张表。当然不一定是真实的表的名称,也可能是表的别名或者临时表。
4、partitions
partitions代表的是分区的概念,表示在进行查询时,如果对应的表都会死分区表,那么这里就会显示具体的分区信息。
5、type
type是非常核心的属性,需要重点掌握。它表示的是当前通过什么样的方式对数据库表进行分访问。
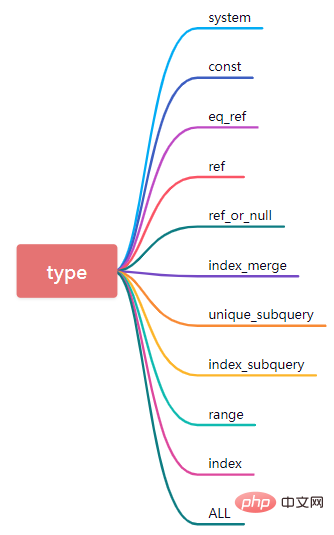
(1)system
该表只有一行(相当于系统表),数据量很小,查询速度很快,system是const类型的特例。
(2)const
如果type是const,说明在进行数据查询的时候,命中了primary key或唯一索引,此类数据查询速度非常快。

(3)eq_ref
在进行数据查询的过程中,如果SQL语句中在表连接情况下可以基于聚簇索引或者非null值的唯一索引记性数据扫描,那么此时type对应的值就会显示为eq_ref。
(4)ref
数据查询的时候如果命中的索引是二级索引不是唯一索引,测试查询速度也会很快,但是type是ref。另外如果是多字段的联合索引,那么根据最左匹配原则,从联合索引的最左侧开始连续多个列的字段进行等值比较也是ref的类型。

(5)ref_or_null
这种连接类型类似于 ref,区别在于 MySQL会额外搜索包含NULL值的行。
(7)unique_subquery
在where条件中的关于in的子查询条件集合
(8)index_subquery
区别于unique_subquery,用于非唯一索引,可以返回重复值。
(9)range
使用索引进行行数据检索,只对指定范围内的行数据进行检索。换句话说就是针对一个有索引的字段,在指定范围中检索数据。在where语句中使用 bettween…and、<、>、<=、in 等条件查询 type 都是 range。

(10)index
Index 与ALL 其实都是读全表,区别在于index是遍历索引树读取,而ALL是从硬盘中读取。
(11)all
遍历全表进行数据匹配,此时的数据查询性能最差。
6、possible_keys
表示哪些索引可以被Mysql的优化器进行选择,也就是索引候选者有哪些。
7、key
在possible_keys中实际选择的索引
8、key_len
表示索引的长度,和实际的字段属性以及是否为null都有关系。
9、ref
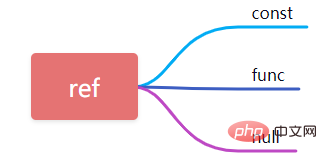
当使用字段进行常量等值查询时ref此处为const,当查询条件中使用了表达式或者函数则ref显示为func,则其他的显示为null。
10、rows
rows列显示MySQL认为它执行查询时必须检查的行数。行数越少,效率越高!
11、filtered
filtered 这个是一个百分比的值,表里符合条件的记录数的百分比。简单点说,这个字段表示存储引擎返回的数据在经过过滤后,剩下满足条件的记录数量的比例。
12、extra
在其他列不显示额外信息在此列进行展示。
(1)Using index
在进行数据查询的时候,数据库使用了覆盖索引,就是查询的列被索引覆盖,使用到覆盖索引查询速度会非常快。不是使用select * ,而是使用select phone_number,就会用到覆盖索引。

(2)Using where
查询时未找到可用的索引,进而通过where条件过滤获取所需数据,但要注意的是并不是所有带where语句的查询都会显示Using where。

(3)Using temporary
表示查询后结果需要使用临时表来存储,一般在排序或者分组查询时用到。
(4)Using filesort
此类型表示无法利用索引完成指定的排序操作,也就是ORDER BY的字段实际没有索引,因此此类SQL是需要进行优化的。
exlpain分析实战
上文中我们阐述了explain在分析SQL语句时,可以通过12个属性来分析SQL的大致执行过程,并以此来判断SQL存在的性能问题。那么接下来我们通过一个实际的例子,来具体看下如何结合explain来实现SQL的性能分析。
其实所谓的Mysql性能问题,大部分都指的是平台出现了慢查询问题。慢查询实际上是可以通过配置进行记录的,把执行时间超过某个设定的阈值的sql都记录下来,当出现问题的时候可以通过记录的慢查询日志进行问题的定位。但是有的时候,出现大量慢查询会导致数据库连接给占满,导致整个平台的出现异常。
实际上我们在产品评价表product_evaluation中是建立了索引的,正常来说应该是可以使用到对应的索引字段进行查询的。但是实际上查询耗时有几十秒的时间,远远超过我们的预期。那我们猜测是不是由于某种原因导致Mysql优化器没有选择对应的索引进行数据检索,最后造成慢查询的发生。到底执行计划是怎样的,还是得借助于explain来看下。

如上文所说,虽然explain有12个字段属性帮助我们进行执行计划的分析,但是实际上常用的核心字段也就几个。我们可以看的出来在possible_key中实际上包含了我们设置的索引的,但是实际上Mysql却选择了PRIMARY作为其实际使用的。那么问题来了,为什么明明设置了索引,但是实际并没有用上,呗Mysql吃了吗?另外为什么之前的业务中没有出现这个问题,而现在出现了?我们需要进行进一步的分析。
我们所建立的idx_evaluation_type实际上是一个二级索引(叶子节点是主键id),对于数千万一张的大表来说,实际上这个二级索引也是非常大的,而且这个字段本身的值就三个,变化不大。因此Mysql的优化器在分析这个SQL的时候发现,如果按照SQL中的索引来获取数据后再根据where条件进行筛选,筛选后的数据还需要回表到聚簇索引中获取实际的数据。
假如通过二级索引筛选出来的数据有几万条,而后还需要进行排序,这些操作都是基于临时磁盘我恩建进行的,Mysql判断这种方式的性能可能会很差,因此优化器放弃了原有的数据查询方式,直接通过主键id对应的聚簇索引来进行数据的获取,因为id本身就是有序的。
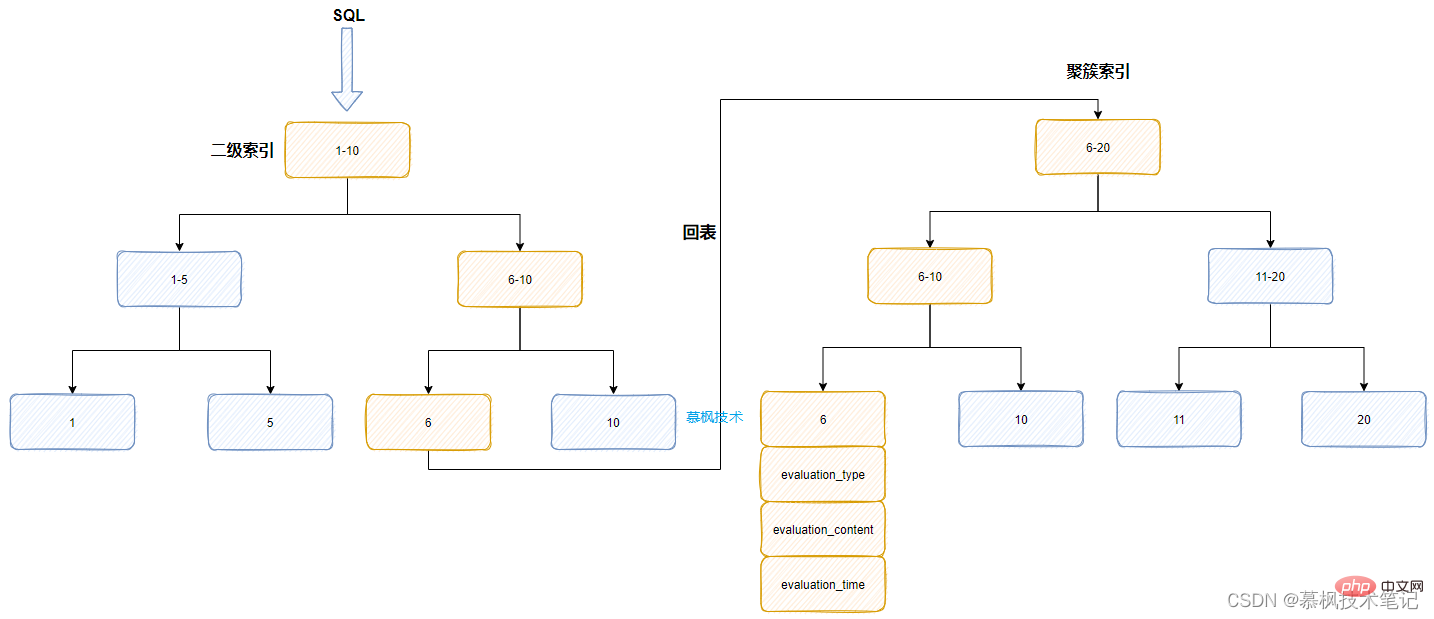
那么知道了查询慢的原因,我们应该怎么进行优化呢?实际上可以在SQL语句中增加force idnex,强制Mysql使用我们设置的二级索引。
SELECT * FROM product_evaluation force index(idx_product_id)WHERE product_id =1 and evaluation_type='GOOD' ORDER BY id desc LIMIT 200
总结
通过上文对于explain使用的介绍,大家在遇到慢SQL问题的时候,可以先通过explain来进行初步的分析,主要明确SQL在Mysql中实际的执行过程是怎样的,如果查询字段没有索引则增加索引,如果有索引就要分析为什么没有用到索引。只要明确具体的执行过程,我们才能确定具体的查询优化方案。
推荐学习:mysql视频教程
以上就是完全掌握Mysql的explain的详细内容,更多请关注php中文网其它相关文章!

声明:本文转载于:CSDN,如有侵犯,请联系admin@php.cn删除
程序员必备接口测试调试工具:点击使用

- 上一篇:mysql怎么查询近一周的数据
- 下一篇:jquery怎样排除第一个元素